斯坦福大学副教授:人工智能与火、电力、书写
发表时间:2023-08-29 11:08:05
文章来源:炫佑科技
浏览次数:270
菏泽炫佑科技
斯坦福大学副教授:人工智能与火、电力、书写

(以下文字经过语音识别转为文字并润色)
尊敬的各位来宾、各位朋友,大家上午好。
首先感谢组委会邀请我参加本次峰会,让我有机会在这里与大家交流。 在这个信息通信技术时代,作为软件研发机构,我们需要思考如何构建AI(人工智能)战略。
我在软件研发领域工作了三十多年,其中十年在大学任教,十年在企业从事软件开发、测试和技术管理,*后十年又回到大学继续深造。软件工程的教学和研究。 我非常关注软件工程,尤其是软件工程的演化过程。
今年3月,我写了一篇文章《》,讨论了GPT(大规模预训练语言模型)出现后软件工程发生的巨大变化,进入软件工程3.0时代。

相信在座的大部分嘉宾都读过《失控》这本书。 近日,该书作者凯文·凯利出版了一本新书,名为《5000天的世界》。 为什么叫5000天呢? 因为大约十年左右的时间,将会发生巨大的变化。
他在谈到新书时提到,人们对人工智能的关注度不够,人工智能被低估。 从长远来看,他认为人工智能对人类的影响就像火、电、文字等一样,具有改造的力量。
*近,我看到一段采访斯坦福大学副教授、人工智能实验室主任吴恩达的视频。 吴恩达是全球人工智能和机器学习领域*权威的学者之一。 他表示:人工智能就像100年前的电力,会给每个行业带来巨大的影响和改变,所有行业都将面临转型。

GPT的发布更是火上浇油。 从去年11月开始,我们就一直在讨论GPT和大模型的话题,每天都可能会发布相关消息。 在中国,有人称之为“百模战争”,类似于多年前的“千团大战”。 华为、科大讯飞、百度等多家公司都推出了自己的机型。 GPT的推出激发了人们的想象力,并像当时一样迅速扩大了市场。 这意味着AI解锁的时刻已经到来,可能比我们过去想象的任何一波AI浪潮都要强大。 在这个快速变革的时代,我们需要拥抱大模式,保持好奇心,与时俱进。

我们也看到了一些很好的例子,比如微软把所有的资源和精力都投入到了人工智能领域,all-in AI。 可以说,微软已经将人工智能视为公司的战略要素。 微软将AI技术和GPT能力集成到其产品中(例如,和),这表明了他们在AI上的战略。
鉴于人工智能技术在软件研发领域的应用还相对不成熟,我们需要建立自己的人工智能战略。 作为每一个软件研发机构,我们都需要开始思考人工智能策略,并逐步建立起来。 过去,我们可能只是尝试了AI技术,但并没有将其作为战略的重要组成部分,而只是抱着尝试的心态来使用。

在软件开发中,我们还没有充分利用人工智能技术。 虽然在一些行业,比如高铁、航空等,人工智能技术的应用相对较多,但我们在软件开发方面的应用仍然不足。 因此,我们需要构建与AI相关的AI战略。 那么,如何构建呢?
我简单将AI战略的构建分为三个步骤,帮助软件研发机构构建AI战略。

首先,我们需要改变对人工智能技术的认知,重新定位其在软件开发中的角色。 过去,我们可能只将AI技术视为一种辅助手段,比如代码编写过程中的代码提示、函数名补全等。 虽然这些功能确实在一定程度上有所帮助,但它们的真正影响是有限的,而且它们只是几个方面的帮助。 在测试领域,我们使用人工智能技术进行GUI测试、API测试等。即使在单元测试中,我们也使用深度神经网络等技术。
然而,这些应用仍然只是一些点的例子,我们需要将这些点连接起来,形成一个更完整的人工智能系统。 这就需要我们从**步开始改变对AI技术的认识,将其视为一种可以覆盖整个软件开发流程的重要能力,而不仅仅是局限于某些特定功能的应用。
接下来,第二步是扩大人工智能的应用范围,逐步向更具挑战性的领域努力。 首先,我们可以从简单的应用入手,比如在开发工具中加入更强大的AI功能,提供更智能的代码补全、自动化测试等功能。 随着我们逐渐熟悉和掌握AI技术,我们可以开始探索更复杂的场景,以提高软件开发的效率和用户体验。
将其变成一个更可行的解决方案,一个真正有效的框架。 过去我们可能只是在一些特定的点上应用了一些AI技术,在GUI测试上取得了一些突破。 但现在情况不同了。 基于大型模型的技术,例如代码生成、代码审查、代码优化和代码解释,使我们能够开辟更广泛的可能性。
过去,很多遗留代码可能无人看管,因为IT人员流动率很高,所以新员工可能无法理解以前编写的代码。 但现在我们可以依靠强大的GPT或者大模型来帮助我们理解这些代码,或者回顾新人的代码。 因此,现在我们可以利用代码大模型,在现有大模型的基础上微调或者优化我们自己的代码,然后训练出适合我们应用的大模型。
两周前,华为发布了盘古模型和代码模型的演示,着实给大家带来了巨大的震撼效果。 现在,我们还可以从大型模型中为用户故事生成验收标准、测试用例和测试脚本。 这里的截图都是我亲自完成的,从头到尾。 但需要人机交互,通过适当引导和不断细化,模型可以更好地应对各种特殊和负面场景的测试用例生成。 所以,从整体上来说,我们的测试方法和过去是完全不一样的。 它采用了AI技术,更加智能。 过去我们只是在几个点上使用自动化测试,本质上是执行测试的自动化,而不是真正的测试自动化。 今天,我们可以看到真正的自动化,不用写一行代码,不用写测试用例和脚本,我们就可以通过自然语言交互自动生成测试用例和测试脚本。
在数字化转型中,我们不再把计算机技术、人工智能技术当作支撑业务运营的工具,而是逐渐将它们融合起来。 这不仅仅是简单的融合,而是更广泛的融合。 未来,或者说从现在开始,人工智能技术将成为我们数字化转型的核心技术,给我们带来更多的机会和可能。
这项技术是我们业务系统的核心力量,正如微软所说,它是决定性的技术。 不同的是,人工智能已经渗透到我们身边,它决定了企业的运营效果和竞争力,这取决于我们对人工智能技术的应用和能力。 这就是我刚才提到的,我认为此时此刻,我们正处于一个软件工程的新时代。 因此,我把传统的软件工程(以瀑布模型或V模型为代表)定义为1.0,把过去所谓的“现代软件工程”(以敏捷为代表)定义为2.0。 从今年开始,我们进入了软件工程的3.0时代,也就是大模型时代、智能化时代,或者说是真正的数字化时代,因为软件的形态发生了巨大的变化。
在1.0时代app开发,软件更多地作为一种产品而存在。 2.0时代,软件作为服务(SaaS)存在,这使得持续交付和持续集成变得有价值。 今天,软件作为一种模型而存在。 我们可以看到,一个合适的GPT模型并不局限于特定的任务,而是具有多种功能。 有了合适的GPT模型,我们就可以执行翻译、文章摘要、代码生成、测试用例生成和许多其他任务。 模型是具有多种功能特性的真实软件。 这些功能特征并不是一一开发出来的,而是模型本身所具备的。
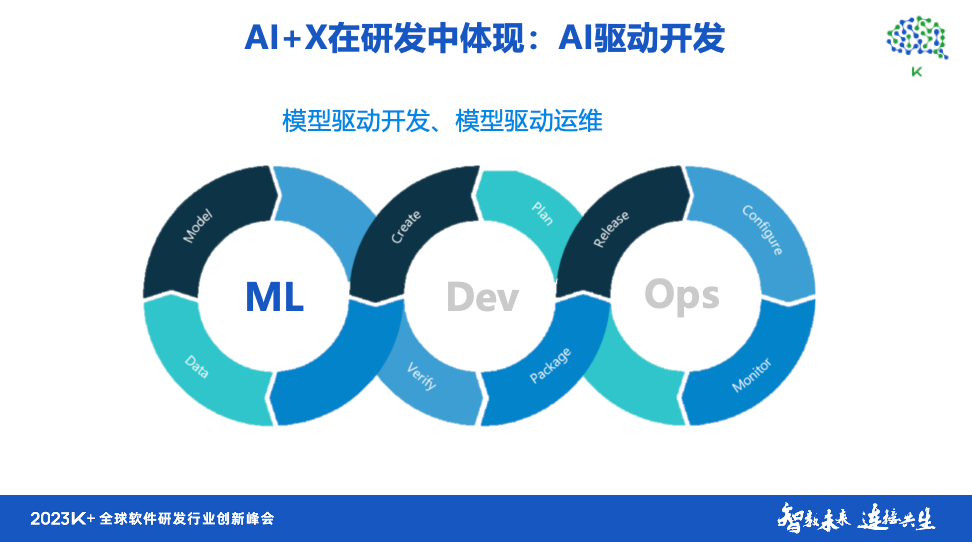
这个时代,模型成为核心,驱动开发和运维。 在1.0时代,我们通常只有一个闭环,而在2.0时代,我们有两个圆()。 而在3.0时代,我们有三个圈子,加入了机器学习(ML)作为驱动力。 之所以用1.0、2.0、3.0来描述,是因为它符合软件演进的过程。 开发软件也是一个逐步迭代的过程,版本(1.0、2.0、3.0……)不断演化。 未来将会有更多的AI原生开发。 因此,很多年前,我们就开始出现云原生。
因为我们进入了云计算时代,所以我们有云原生开发或者云原生平台。 未来AI也可能成为一个平台,我们将会有更多AI原生的应用。 您可能会想,什么是 AI 原生应用程序? 这是从一开始就从AI出发,这将不同于在原有软件中加入AI技术的应用。 就像一个平台或工具是从以云为中心的角度开始的,而不是从传统的单一系统慢慢演变成云系统。 因此,如果从一开始就构建一个云系统或平台,它就会更有弹性、更有韧性,更能体现这种能力。 这与构建一个可能庞大或复杂的系统不同,因为云的力量和弹性不会得到体现。

第二步,我们从简单的角度出发,以便可以参考一些工具。 如果您认为不需要参考工具,因为有些人喜欢重新发明轮子,那么您可以自己制作,这也很好。 但我们通常鼓励使用现成的工具(如果有),就像我们对开源大型模型所做的那样。 近日,刚刚有消息称,Meta()与微软联合发表声明:Llama 2开源版本免费用于商业用途。 因此,我们可以基于开源大模型Llama 2,构建自己的大模型。 此外,与过去不同的是,我们现在认识到模型的价值,更认识到数据的价值。 因为我们模型的力量取决于良好的数据。 如果我们有好的数据,我们的模型就会有更好的能力和更准确的输出。
所以,我们首先要建立自己的大模型。 你可以基于开源大模型构建自己的模型,并在基础大模型上进行微调,但*简单的方法是直接调整API或调用其他大模型的接口。 另一种方法是利用过去积累的知识库或数据,甚至建立一个包含知识或规则的数据库来保存这些数据。 然后,我们可以通过某种方式将它们绑定到大模型上。 通过这些知识或者数据,我们可以做进一步的优化或者调整,比如利用知识库的规则来验证大模型输出结果的准确性,也可以适应我们的业务,解决大模型的时效性问题。数据。
然而,对于更有实力的大企业来说,他们会训练自己的大模型,但这是*困难、成本*高的方法。
下一步是应用这个大型模型的能力。 我们一致认为,代码是大型模型应用的重要领域。 因此,我们需要一个编程助手来帮助我们生成代码、审查代码和解释代码、以及测试。 尽管我们有编程助理和测试助理可以生成代码和测试,但开发人员和测试人员仍需要进行评审。
更进一步,我们可以找业务分析师进行业务分析,了解客户和用户的需求,帮助梳理需求。 同时,大型机型可以在运维中发挥重要作用。 微软专家将在AIDD会议上分享这方面的案例,发现线上问题,诊断异常问题,通过大模型对问题进行分类。
这样,基于大模型的工程平台就会逐渐成长起来,可以帮助我们进行任务规划。 *近也有一些研究这项工作的工作。 该平台还可以帮助我们进行自我反思,因为大型模型的短期记忆是有问题的。 通过其他手段或者提示工具,比如GPT发布的代码解释器插件,可以对文件进行存储和保存,可以增强大型模型的长期记忆能力。
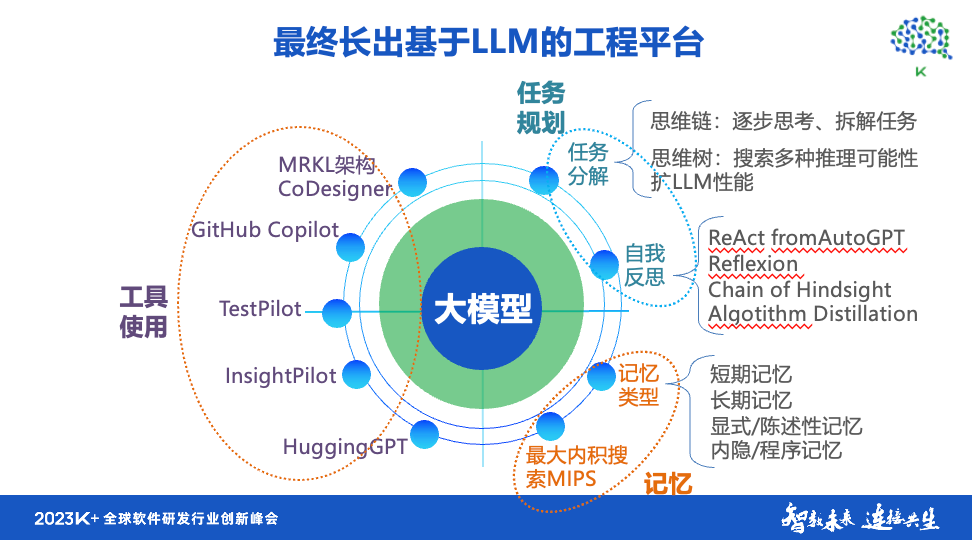
我们讨论了工具的内容,*终可以搭建一个基于大模型的工程平台,进一步形成一个完整的端到端的大模型应用框架。 通过该框架强调了前面提到的数据的重要性。
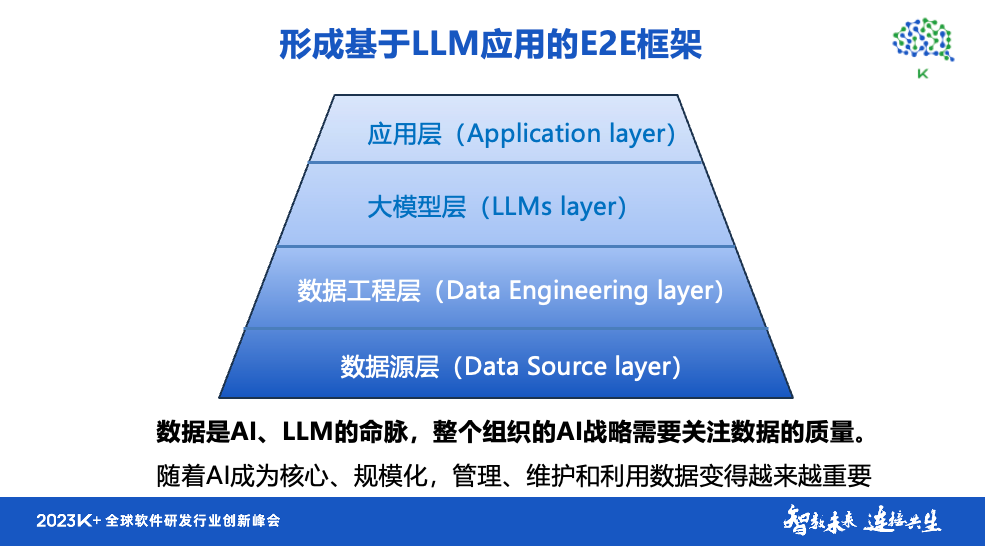
在数据层面,我们需要在数据资源、数据管理和处理方面进行投入。 因为*终每个组织或团队应用的效果取决于数据的质量和数据处理能力。 数据处理还反映了数据自我管理和数据工程技能。 这里显示的大型财务模型的第二层是数据工程层。 我们应该清楚这一点,因为大数据的概念已经讨论了十年。

接下来的第三步是组织和流程的规范化。 由于人的问题一直是*困难的问题,所以我们将在第三步中处理它。 组织是可以重新配置的,我们可以根据大模型能力的应用不断缩小团队规模。 有一种极端的说法,一个强大的人可以在大模型(作为助手)的帮助下独自完成一个产品,但这很夸张,而且不需要那么多人。 我们需要更多有能力的研发人员和更多的助手,就像海军陆战队一样,拥有强大的工具和武器。
今天我们也需要好的工具来提升我们的能力,这样我们的竞争力才会有很大的不同。 所以很多初级工程师的职位基本上可以取消,但同时我们可能会招收更多的高端人才。 各种角色应该都有,包括产品经理、开发和测试职位,但还需要更高级的开发和测试人员,每个人可能还有一些助理,比如代码助理和测试助理。 通过这种方式,我们能够使团队更加精简。 这就是为什么我们提到特种部队或美国海军陆战队,他们拥有非常好的工具来支持他们的行动。 因此,他们人数虽少,却能成就大事,甚至可能比数百人的团队更有效。 这就是工具的力量。
人工智能的力量对我们来说非常重要。 其中,人机协作发挥着重要作用,而AI这个超人,并不只是作为助手而存在。 在前面的讨论中,大模型主要扮演的是编程助手、测试助手和运维助手的角色。 它也可以作为 BA 助理存在,但这并不是唯一的情况。 当你水平低的时候,也许他是你的师傅,你是他的助手。 或者说,当我们的能力相当时,我们可以优势互补。 他可能在某些方面更强斯坦福大学副教授:人工智能与火、电力、书写,而你可能在其他方面更强,这会互相帮助。 他拥有丰富的知识,几乎涵盖了全世界的知识,而你的知识却非常有限。 虽然他各方面都不比你强,但很多时候他就是你的师父。 如果涉及到建筑,他可能是你的顾问和专家,可以给你建议和意见,虽然他不能自己做建筑工作。 他可以向你传授知识,解释什么是好的设计模式,或者什么是适合你需求的设计模式。 因此,他可以提供更多的帮助。 在每个环节、不同项目、不同时期,各自的能力都会有所不同。 所以,这种合作关系就发生了变化,有时候你是他的助手,他是主宰;有时候你是他的助手,他是主宰; 有时他是助手,你是主人。 所以我认为我们应该从更广泛的角度来看待这种伙伴关系,而不仅仅是作为助理。
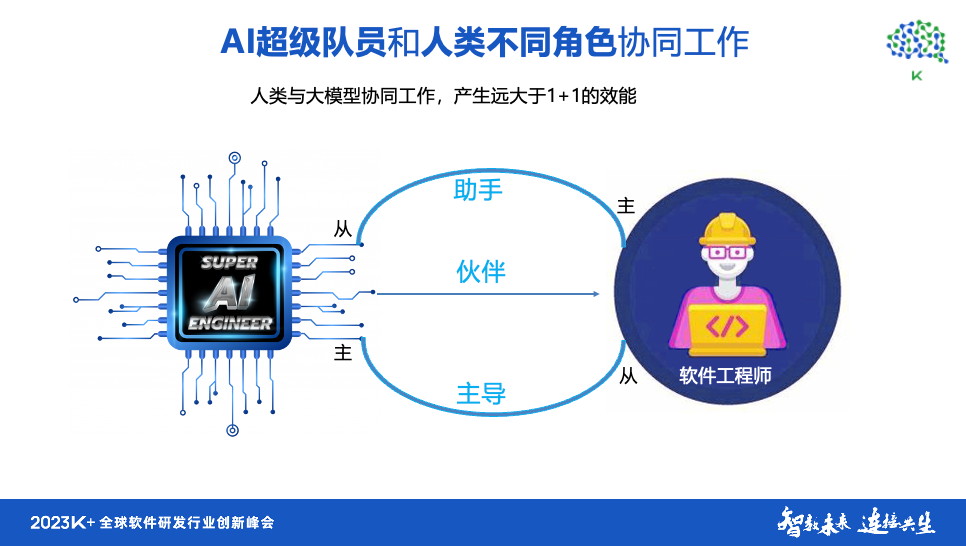
另一方面,确实存在一个问题,如果你用来生成代码或者测试用例,可能会不太方便,因为你仍然需要逐字输入提示词。 我们能不能有一个平台来支持这种工作,包括生成提示词的助手,甚至可以帮助你生成更好的提示词。 或者多个研发人员协作共同生成测试用例,生成更好的提示词。 这样,我们之间的合作就会更加顺利。
当然,如果您的组织不想采取任何行动,也没关系,因为五年或十年后,大多数企业将不复存在。

如果你真的想在竞争中生存下来,你可以乘坐下一趟航班,因为我们8月18-19日将举办AiDD峰会,期待你的参与。
谢谢你们!
下载演讲PPT:关注本公众号,输入“AI攻略”即可获取下载地址。
炫佑科技专注互联网开发小程序开发-app开发-软件开发-网站制作等