编程助手:给软件工程带来了什么?
发表时间:2023-09-22 20:04:55
文章来源:炫佑科技
浏览次数:148
菏泽炫佑科技
编程助手:给软件工程带来了什么?
01
它给软件工程带来了什么?
从清华大学获得博士学位后,我加入了微软亚洲研究院,从事软件系统程序分析方面的研究。 同时,我也一直关注机器学习领域的发展。 如今,科技确实让几乎每个人都感到震惊。
接下来我们就进入到这项技术的实用内容。 今天的演讲将分为四个部分。
在**部分中,我们将概述对软件工程的影响,不仅仅是程序员如何提高工作效率,而且还探讨对整个软件工程的影响。
首先,**个方面让大家写代码变得更快、更容易。 我想这个话题就不用赘述了,因为相信很多人都经历过。 出现之后,另一个新产品也值得关注——代码搜索领域的领先公司正在推出一款产品Cody(虽然尚未发布公测版),该产品提供了帖子中的问答功能-时代。 Cody 将结合您的领域知识并根据现有代码给出答案。 我认为这个产品值得大家关注。
编程助理
但总体来说,我们现在看到的实现能力并不能生成复杂的项目级代码,只能帮你写一些微代码。 至于生成工程代码,我们可能还需要等待一段时间。 比如《流浪地球》中,机器人可以为你重写整个操作系统。 我想这种幻想还只存在于小说里。 至于这个能力什么时候实现,我无法预测,因为任何预测都有可能被打脸。 不那么悲观的话,我们的工作应该还能再保住几年。 这是影响的**个维度。
但对软件工程的影响不仅仅是让个人更快地编写代码那么简单。 我们可以问一个问题:如果你团队中的每个人都快10倍,那么项目进度会快10倍吗? 这里的每个人都是技术经理,显然答案是否定的。 因为在从创建到*终交付的整个过程中,编写代码可能只占10%-20%,而且软件工程中有很多复杂的组织和流程因素。
因此,我们还需要看看能否解决软件工程中的信息不对称问题。 因为当人数增加时,信息不对称就会存在,流程摩擦也会增加。 想想我们每天有多少次会议以及我们花在会议上的时间百分比是多少。 AI能在这方面发挥作用吗? 这是一个与以前同样重要的维度。
如果您的组织中有一位研发有效性顾问可以回答有关您的项目和公司的问题,那么它可以帮助减少信息不对称并消除组织中的流程摩擦。 当然,有些会议需要真人交流,但如果能直接回答一些问题,可能会减少20%的会议时间,这也是一种效率。 因此,这个值也是一个非常重要的维度。 我们的许多客户都期待着这种功能。
02
从研发数据来看
第二部分我们将从研发数据的角度来讨论,因为任何人工智能技术的训练和使用都需要数据作为原材料。 因此,我们必须从数据的角度来思考这个问题。

大规模模型的基石是基于公开数据中的海量参数进行训练,规模达到千亿级。 但它不了解私域信息、组织、团队等相关知识。 那么,如何将这些知识转移到它上面,是我们目前面临的*大瓶颈。
数据基本上可以分为两类:一类是你的代码,它存储了你的大部分软件知识;另一类是你的代码。 另一种是关于你的软件工具和开发行为的所有数据,比如你的工具中的所有通信交互过程数据,这部分数据是在代码之外的。
具体来说,我们有三种做法: *右边的是使用大模型*典型的方法,即提供hints()。 与大型模型交流时,您不仅需要提出问题,还需要为其提供一些背景信息和一些示例来解释您想要做什么以及您的情况。 这里*大的挑战是你只能提供非常有限的信息,例如 4K 或 8K。 如果信息太少,大模型无法回答你关于服务和知识的问题。 这个带宽非常小。
*左边的方法是用自己的数据来训练一个大的模型,需要修改和更新它的参数。 然而,这种方法需要大量的时间和资源。 中间的方法是自己训练一个小模型,向大模型学习,然后对其进行微调,使其更适合您的特定任务。
在实践中,选择哪种方法取决于您的具体情况和需求。 无论我们选择哪种方法编程助手:给软件工程带来了什么?,我们都需要了解大型模型的优点和局限性,并在实践中挖掘它们的潜力。
总体来说,我们目前探索的方向是*右边的第三条路。 选择这条道路的逻辑是核心思想。 这个想法的成功在于利用全球公共信息和1000亿个参数来训练通用模型,而不是针对特定领域收集数据并优化模型。 当需要解决特定问题时,需要一个小样本,模型就能够学习并回答问题。 所以我们仍然想走这条路。
03

如何打造高质量的研发数据基础?
在第 3 部分中,我们将介绍构建高质量研发数据基础的五个步骤。 只有保证数据库的高质量,才能可靠地解决特定领域的问题。
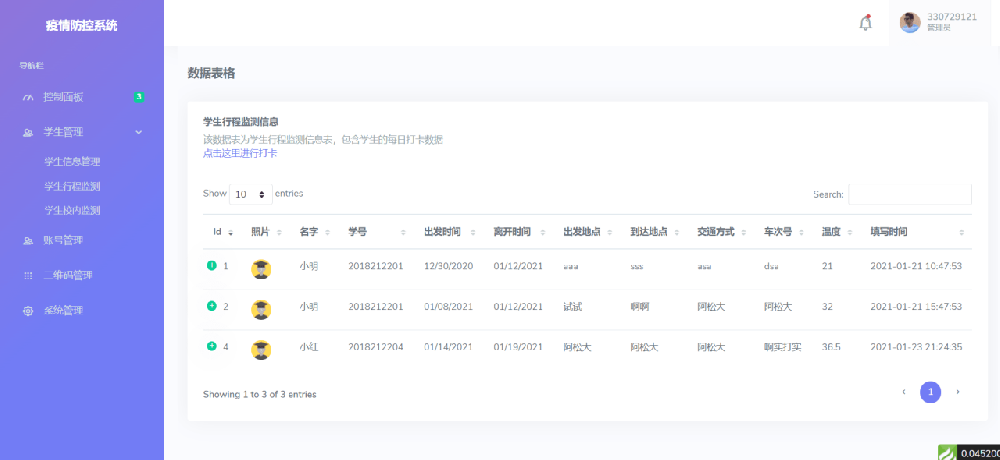
**步是完成原始数据的积累。 我们意识到,在研发中,这些数据本身就是重要的资产和信息来源。 我们建议使用像这样的开源工具来快速度过这一初始阶段。
第二步,获得数据后,我们会面临数据质量问题。 数据健康状况很重要,因为如果您向算法提供 60 分的数据,您将不会得到 90 分的结果。 因此,我们建议使用代码分析技术来校准和整合数据,以保证数据质量。
第三步需要独立分析,利用BI或可视化工具解读数据中的信息,深入探究原因,推动测量-分析-审查-改进的循环。

第四步,以目标为导向,采用GQM(目标-问题-度量)方法,基于健康数据进行系统洞察,进一步复用和丰富模板,积累知识。
第五步,以实现智能交互为基础,满足灵活多样的信息需求。 将自然语言转换为SQL的研究领域早已存在,以它为代表的新一代自然语言处理工具将为这一领域带来新的活力。
04
在实际研发表现中
它在数据方面的表现如何?
第四部分,我们深入探讨上述第五步——智能交互,探索基于可靠的研发数据可以实现哪些功能。
我们基于真实的数据表,测试理解人类常识、找到正确表格、处理复杂抽象问题的能力。
**次测试表明,它具有比较全面的人类常识,可以直接找到“开放问题”、“问题合作”等表达对应的数据。 这意味着我们不需要提供额外的数据字典来帮助它理解某个细节。 子区域。

第二个测试显示了处理复杂数据表的能力。 我们提供了 9 个相互关联的表,其中有许多重复的数据字段,并成功找到了正确的表并输出了正确的 SQL 查询。
第三次测试表明,当所问的问题模糊时,尝试理解方向也是合理的。 我们的问题包括“*近”和“PR审查很难”等不准确的表达app开发,而SQL查询使用了“上周”、“PR评论长度> 500”和“PR评论数量> 5”等特定语句。 以及合理的猜测。
第四个测试不是基于研发数据,但是很有趣,所以我想和大家分享一下。 我们用自然语言处理数据集中的一个超难问题来测试。 它给出的**个SQL查询是错误的,然后我们没有给出任何提示或反馈,只是重复提问。 在接下来的几次尝试中,成功给出了多种正确的解决方案。
这说明可以通过多次尝试实现自我验证,提高数据解读的准确性。